How We Stay Sane With A Large AWS Infrastructure
Jon Dokulil is the VP of Engineering at Hudl. He’s been with Hudl since the early days and has helped grow the company from one customer to over 50,000 today. Jon is passionate about the craft of building great software and is particularly interested in distributed systems, resilience, operations and scaling.
We’ve been running hudl.com in AWS since 2009 and have grown to running hundreds, at times even thousands, of servers. As our business grew, we developed a few standards that helped us to make sense of our large AWS infrastructure.
Names and Tags
We use three custom tags for our instances, EBS volumes, RDS and Redshift databases, and anything else that supports tagging. They are extremely useful for cost analysis but are also useful for running commands like describeInstances.
- Environment – we use one AWS account for our environments. This tag helps us differentiate resources. We only use four values for this: test, internal, stage or prod.
- Group – this is ad-hoc, and typically denotes a single microservice, team or project. Due to several ongoing projects ongoing at any given time, we discourage abbreviations to improve clarify. Examples at Hudl: monolith, cms, users, teamcity
- Role – within a group, this denotes the role this instance plays. For example RoleNginx, RoleRedis or RoleRedshift.
We also name our instances. To facilitate talking about them, which can help when firefighting. We use Sumo Logic for log aggregation and our _sourceName values match up with our AWS names. That makes comparing logs and CloudWatch metrics easier. We pack a lot of information into the name:
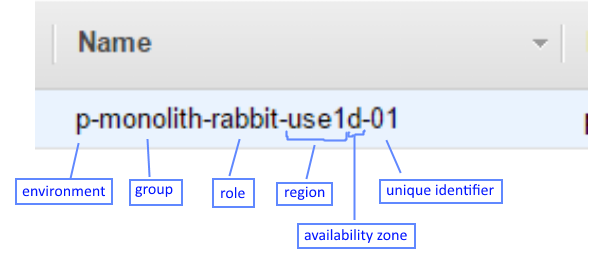
At a glance I can tell this is a production instance that supports our monolith. It’s a RabbitMQ server in the ‘D’ availability zone of the ‘us-east-1’ region. To account for multiple instances of the same type, we tack on the ‘id’ value, in this case it’s the first of its kind. For servers which are provisioned via Auto-Scaling Groups, instead of a two-digit number we use a six-digit hash. Short enough that humans can keep it in short-term memory and long enough to provide uniqueness.
Security Groups & IAM Roles
If you are familiar with Security Groups and IAM Roles, skip this paragraph. Security groups are simple firewalls for EC2 instances. We can open ports to specific IPs or IP ranges or we can reference other security groups. For example, we might open port 22 to our office network. IAM Roles are how instances are granted permissions to call other AWS web services. These are useful in a number of ways. Our database instances all run regular backup scripts. Part of that script is used to upload the backups to S3. IAM Roles allow us to grant S3 upload ability but only to our backups S3 bucket and they can only upload, not read or delete.
We have a few helper security groups like ‘management’ and ‘chef’. When new instances are provisioned we create a security group that matches the (environment)-(group)-(role) naming convention. This is how we keep our security groups minimally exposed. The naming makes it easier to reason about and audit. If we see an “s-*” security group referenced from a “p-*” security group, we know there’s a problem.
We keep the (environment)-(group)-(role) convention for our IAM Role names. Again, this lets us grant minimal AWS privileges to each instance but is easy for us humans to be sure we are viewing/editing the correct roles.
Wrap.It.Up
We’ve adopted these naming conventions and made it part of how folks provision AWS resources at Hudl, making it easier to understand how our servers are related to each other, who can communicate with who and on what ports, and we can precisely filtering via the API or from the management console. For very small infrastructures, this level of detail is probably unnecessary. However, as you grow beyond ten, and definitely once past hundreds of servers, standards like these will keep your engineering teams sane.
Jon can be reached at www.linkedin.com/in/jondokulil